总访问量 ... 次
总访客数 ... 人
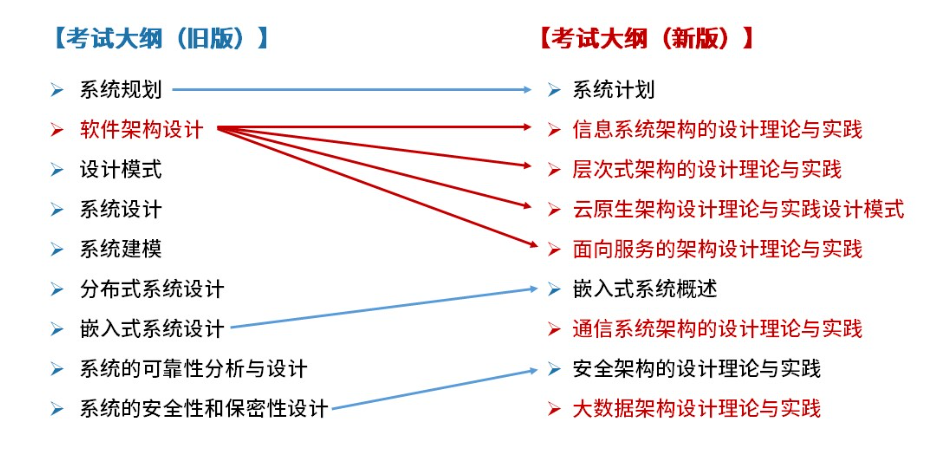
考试大纲,新旧大纲对照如下:
案例分析特点:
对于以下内容要求必须掌握,可能出现在必答题:
案例分析对考生的要求:
案例分析偏主观性,需要了解出题人的意图,再来答题,易得高分。 答题前标出问题要点,以此作为主要线索进行分析和思考。然后对照问题要点仔细阅读正文,通过定性分析或者定量估算,构思答案的要点。 最后以最简练的语言写出答案。
遇到新的知识点,不要慌,稳住心态。列条目回答问题,把自己认为对的都写上。 分析题目问题的倾向性,从题干上总结答案,顺势答题。